
高阶综合(HLS)推动下一代 AI 加速器的发展
今天我们周围的一切都在变得更加智能。人工智能(AI)不仅仅是一种数据中心应用,在我们日常与之交互的各种嵌入式系统中也能够发现AI。我们希望与这些系统进行对话和手势交流,期待它们能够识别和理解我们,这种智能不仅使这些系统的功能更加完善、使用更为便捷,同时更加安全和可靠。

所有这些智能都来源于深度神经网络的进步。神经网络的关键挑战之一是计算复杂度。小型神经网络可能需要数百万次的乘积累加运算(MAC)才能产生结果,而大型神经网络则可能需要数十亿次,像大语言模型等复杂网络可能需要达到万亿级的计算量。这种级别的计算需求超出了嵌入式处理器的承载能力。
在某些情况下,这些推理计算可以通过网络被转移到数据中心。越来越多的设备拥有快速且可靠的网络连接,使得这种方式成为许多系统的可行之选。然而,也有很多系统具有严格的实时要求,即使是最快最可靠的网络也无法满足。例如,任何有自动化能力的系统(如自动驾驶汽车或无人机)都需要比离线数据中心更快地做出决策。还有一些系统处理了不应该通过网络传输的敏感数据,而且传输内容会增加黑客攻击的风险。由于性能、隐私和安全等原因,某些推理操作需要在嵌入式系统上完成。
对于简单的网络来说,嵌入式 CPU 就可以处理这些任务,例如,一个树莓派就能部署一个简单的物体识别算法。而对于更复杂的任务,嵌入式 GPU 以及针对嵌入式系统的神经处理单元(NPU)可以提供更强的计算能力。但是,要想获得更高水平的性能和效率,需要构建一个定制化的 AI 加速器。
无论是针对 ASIC 还是 FPGA,设计新的硬件都是一项艰巨的任务,但它能使开发者能够取得现成组件无法达到的性能和效率水平。和有着多代产品设计经验的设计师相比,普通开发团队如何才能构建一个更好的AI加速器呢?其中一个方法是通过针对正在执行的特定推理来定制实施方案,这样的效果会比通用解决方案更胜一筹。
在开发者通用 AI 加速器构建 NPU 时,其目标是支持任何可能的神经网络。他们希望获得尽可能多的设计输入,因此必须使设计尽可能通用,不仅如此,他们还希望在设计中内置一定程度的“future proofing”,以支持几年后可能出现的任何网络。而在技术快速发展的背景下,这并非易事。
一个定制化加速器只需支持一个或几个特定的网络。这种自由度允许将在加速器实施过程中的可编程元素固定在硬件中,使得硬件比通用硬件更小且更快。在图像和滤波器尺寸固定的情况下,一个专用卷积加速器的速度可比设计良好的通用 TPU 快上 10 倍。
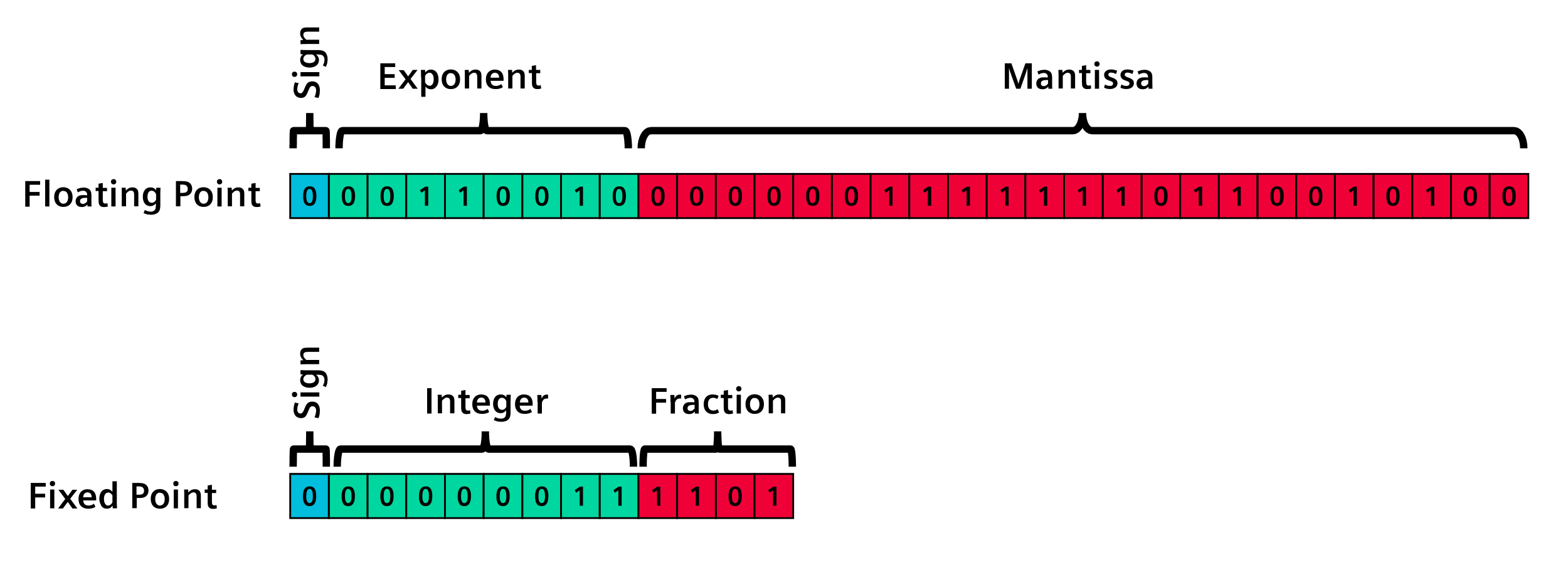
通用加速器通常使用浮点数。这是因为几乎所有神经网络都是在使用浮点数的通用计算机上用 Python 开发的。为了正确支持这些神经网络,加速器必须支持浮点数。然而,大多数神经网络使用接近 0 的数值,并且需要较高的精度,而浮点乘法器体积庞大,如果不需要它们,从设计中去除可以节省大量面积和功耗。
一些 NPU 支持整数表示法,有时还支持多种大小。然而,支持多种数值表示格式会增加电路复杂性,进而消耗电力并加大传播延迟。选择一种表示格式并专门使用,可以实现更小、更快的实现。
在构建定制化加速器时,并不局限于 8 位或 16 位,任何尺寸都可以使用。选择正确的数字表示,或对神经网络进行 “量化”,可以优化数据和运算器的大小。量化可以显著减少需要存储、传输和操作的数据量。减少权重数据库的内存占用和缩小乘法器的尺寸可以显著改善设计的面积和功耗。例如,一个 10 位定点乘法器比一个 32 位的浮点乘法器小约 20 倍,功耗约为后者的 1/20。这意味着设计可以更小巧、更节能。使用更小的乘法器,设计人员也可以选择使用该区域,部署 20 个可以并行运行的乘法器,从而在使用相同资源的情况下产生更高的性能。
在构建定制化机器学习加速器时,有一个挑战是创建神经网络的数据科学家通常不了解硬件设计,而硬件设计师也不了解数据科学。在传统设计流程中,他们会通过“会议”和“规范”来传递知识和分享想法,但显然,这些方法也并不会通过信息交流得到有效传递。
通过高阶综合(High-Level Synthesis, HLS),数据科学家生成的实施方案不仅可以作为可执行参考,还可以作为硬件设计流程的机器可读输入。这就避免了在设计流程中手动重新解释算法,从而避免既缓慢又易出错的手动过程。HLS 从算法描述中合成 RTL 实现。一般来说,算法用 C++ 或 SystemC 描述,但像 HLS4ML 这样的设计流程能使 HLS 工具能够直接从机器学习框架中获取神经网络描述。
HLS 能够以一种在机器学习框架中尚不普及的方式对量化进行实际探索。为了充分理解量化的影响,需要对算法进行微精确的实现,包括溢出、饱和和舍入等影响的特征描述。目前,这只适用于硬件描述语言(HDL)或 HLS 微精确数据类型。随着机器学习的普及,更多的嵌入式系统将需要部署推理加速器。HLS 是一种实用且行之有效的构建定制加速器的方法,加速器针对特定应用进行了优化,提供比通用 NPU 更高的性能和效率。
了解更多信息:高阶综合推动下一代边缘 AI 加速器的发展






